1.验证集与测试集有什么区别?为什么要分训练集、验证集和测试集?测试集与验证集的存在主要是为了把调参与评估泛化能力分为两个相对独立的步骤,体现了正交化思想。 验证集一般用于进一步确定模型中的超参数(例如正则项系数、神经网络中隐层的节点个数,k值等),而测试集只是用于评估模型的精确度(即泛化能力)。 举个例子:假设建立一个BP神经网络,对于隐含层的节点数目我们并没有很好的方法取确定,此时一般将节点数设为某一具体的值,通过训练出相应的参数后,再由验证集取检测该模型的误差; 然后再改变节点数,重复上述过程,直到模型在验证集上误差最小。此时的节点数可以认为是最优节点数。但是这只是在验证集上的表现最优而已,事实上在调整节点数的这个过程当中, 我们已经不知不觉的让调整节点数的方向往达到验证集最小误差这个目标去了。 但事实上,在验证集误差最小通常并不代表在整个数据集上的误差也会小(因为我们是利用验证集上的表现来调整超参数的,因此在调整超参数的过程当中,验证集的误差在不断减少是必然的), 因此需要另外一个数据集来测试模型真正的泛化能力,即测试集。 测试集是在模型确定好所有参数之后,根据测试误差来评判这个模型好坏的一个数据集。 ( 测试集用的次数越少越好。)转载来源:https://www.jianshu.com/p/449ab7ce04d2
2. rank & mAP参考自:http://yongyuan.name/blog/evaluation-of-information-retrievalmAP(mean average precision),用于衡量算法的搜索能力AP(Average Precision)是希望正确的结果要优先出现这种概念的具体指标。 mAP是AP的延伸应用,取多次查询之AP的均值来代表查询(或检索)系统的准确度。 rank,搜索结果中最靠前的一张图是正确结果的概率,一般通过实验多次采取平均值。
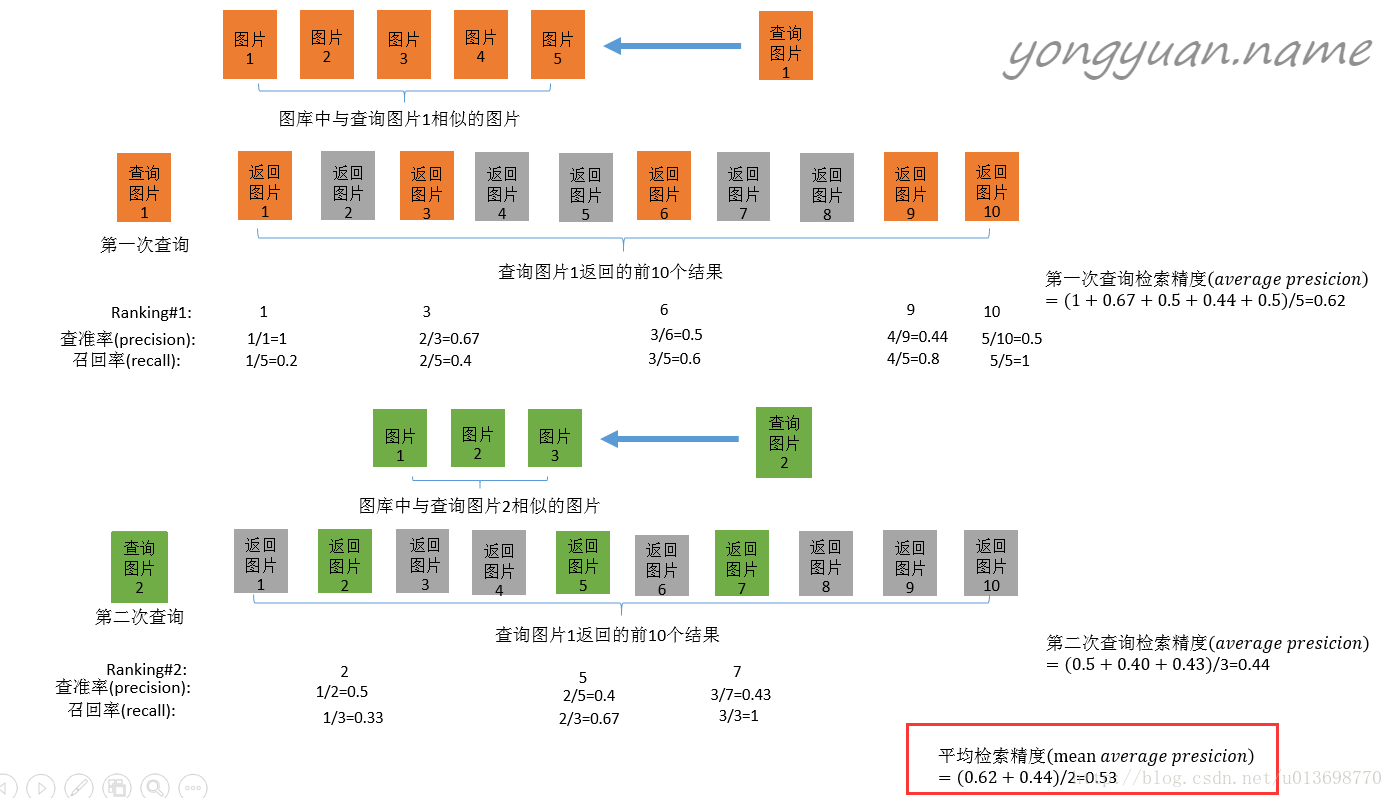
如图所示,